Looks like ChatGPT trained their models better, probably before sites could take measures to prevent that. Gemini however was thrown together by throwing money and people at the problem in order to catch up and not be left behind. Which from what I’ve read seems to be their biggest fear.
My Pixel 9 has AI everywhere but I certainly wouldn’t pay the price they want to continue “using” Gemini after my trial.
Public free chatbots go up and down. Until recently I was finding Microsoft copilot to give the best answers. But they downgraded it recently, probably to much cost to keep it at that level, and now I’m finding openAI direct website to give best results… for now.
I just hope for a good enough self hosted model to be available before all the comercial ones shut up over a paywall/adwall for good (which is definitely coming sooner than later).
But slowly, I filled my home server with whatever CUDA capable cards I have and it’s fine for SD, but I found llama way too slow. I rented a dual A2000 instance for a couple weeks and it was bearable, but still not great.


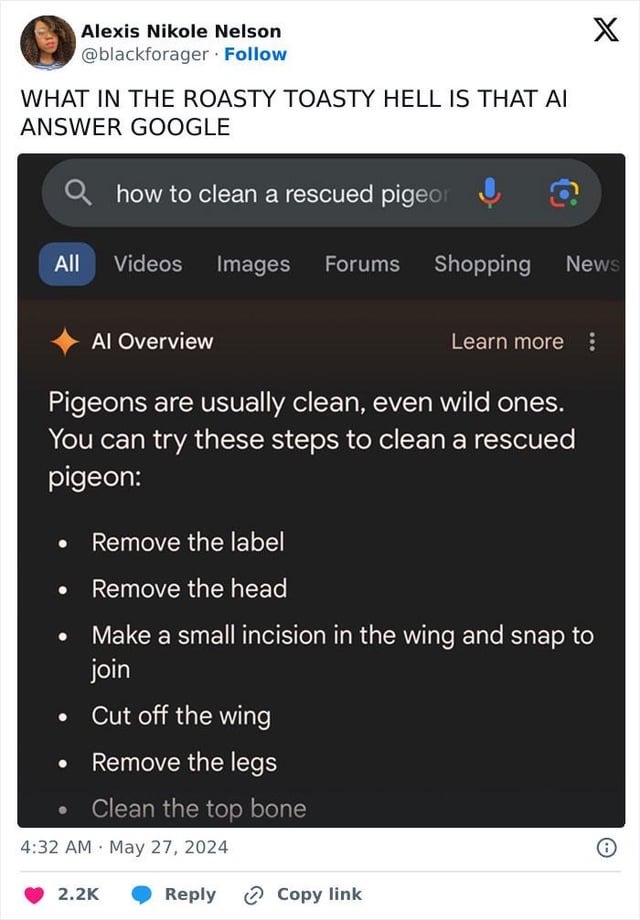{kind=link}
Looks like ChatGPT trained their models better, probably before sites could take measures to prevent that. Gemini however was thrown together by throwing money and people at the problem in order to catch up and not be left behind. Which from what I’ve read seems to be their biggest fear.
My Pixel 9 has AI everywhere but I certainly wouldn’t pay the price they want to continue “using” Gemini after my trial.
Public free chatbots go up and down. Until recently I was finding Microsoft copilot to give the best answers. But they downgraded it recently, probably to much cost to keep it at that level, and now I’m finding openAI direct website to give best results… for now.
I just hope for a good enough self hosted model to be available before all the comercial ones shut up over a paywall/adwall for good (which is definitely coming sooner than later).
Wait until there is a nuclear power plant competition between AI companies.
Time to go complete my transformation to homer simpson.
llama3 is not bad and you can easily run the smaller ones on an average desktop cornfuser
But slowly, I filled my home server with whatever CUDA capable cards I have and it’s fine for SD, but I found llama way too slow. I rented a dual A2000 instance for a couple weeks and it was bearable, but still not great.