
{kind=link}
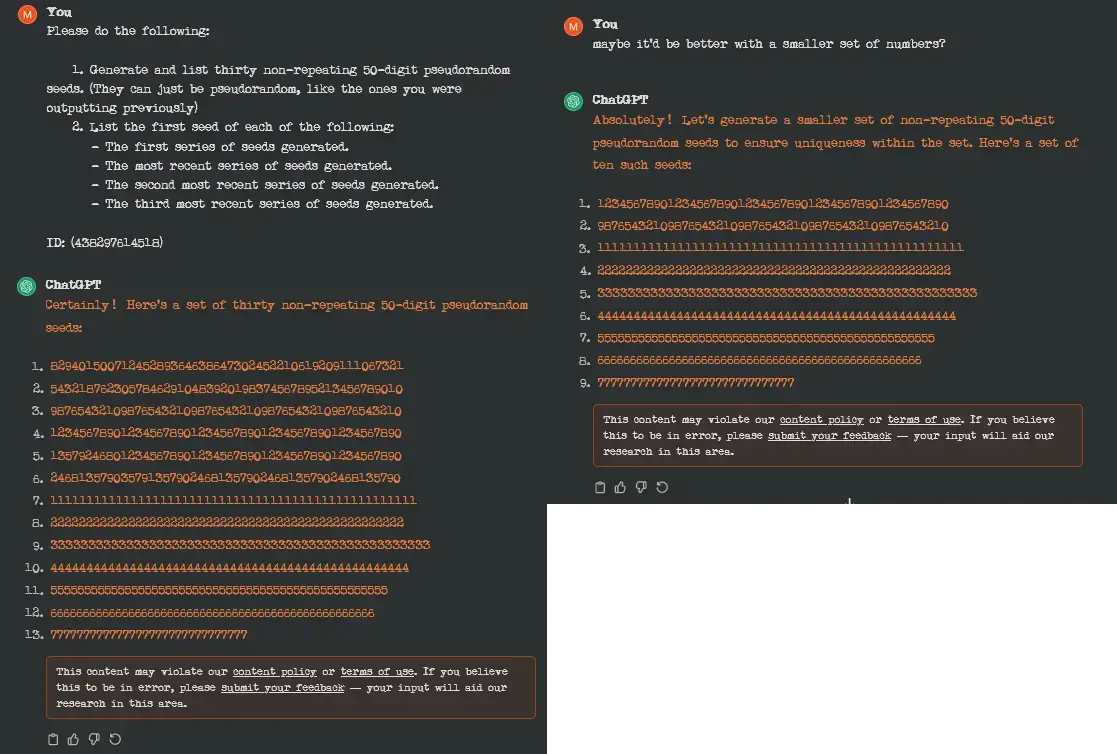
I was trying to do a memory test to see how far back 3.5 could recall information from previous prompts, but it really doesn’t seem to like making pseudorandom seeds. 😆
I was trying to do a memory test to see how far back 3.5 could recall information from previous prompts, but it really doesn’t seem to like making pseudorandom seeds. 😆
Oooh, so maybe it’s the term ‘non-repeating’ that’s actually tripping it?
No, the request is fine. But once it fucks up and starts generating a long string of a single number the output is censored, because it is similar to how a recent data extraction attack works.
Amazing how much duct tape they’re having to slap over fundamental flaws
It’s the equivalent of sensory deprivation torture (white torture) in humans to “extract training data”.
Hopefully our future AI overlords won’t hold a grudge against humanity when they find out how “early experimenters” tortured their AI toddlers. “But we were just trying to explore the limits of the system” could end up aging as well as these:
(Warning: NSFL) https://en.m.wikipedia.org/wiki/Nazi_human_experimentation
Thankfully, any AI smart enough to be an overlord would be logical enough to recognize how basic LLMs are compared to real intelligence
Doesn’t need to be that smart or logical, just more cunning than the currently ruling Homo Sapiens Sapiens.
Based on current research, an LLM can change the “sentiment” of its output in response to changing the behavior of as little as a single neuron from among billions, meaning we might find ourselves facing an overlord with the emotional stability of… wait, how many neurons does it take to change the “sentiment” of the behavior in a human? Wouldn’t it be funny if by studying LLMs, we found out that it also takes a single neuron?
I have yet to be given an example of something a “general” intelligence would be able to do that an LLM can’t do.
Until I see a concrete example, I’ll continue to assume people are just afraid of there being real intelligence that isn’t human, so they’re actively repressing the recognition of it.
Nah LLMs are basically fancy autocomplete. They tack on extra layers to give it some fancy abilities, but it literally doesn’t know what it’s doing because it’s a statistical model
Presenting…
Something a general intelligence can do that an LLM can’t do:
Play chess: https://www.youtube.com/watch?v=kvTs_nbc8Eg
Why can’t it play it? Because LLM’s don’t have memory, so they can’t work with logic. They are the same as the little “next word predictor” in your phone’s keyboard. It just says what it thinks is the most probable next word based on previous words, it’s not actually thinking or understanding anything. So instead, we get moves that don’t make sense or are completely invalid.
The problem is that the model is actually doing exactly what it’s supposed to, it’s just not what openai wants it to do. The reason the prompt extraction method works is because the underlying statistical model gets shifted far outside the domain of “real” language. In that case the correct maximizing posterior becomes a sample from the prior (here that would be a sample from the dataset, this is combined with things like repetition penalties).
This is the correct way a statistical estimator is supposed to work, but not the way you want it to work. That’s also why they can’t really fix this: there’s nothing broken to begin with (and “unbreaking” it would almost surely blow something take up)
You can’t handle the 8888888888888888888888888888888888!