
Ok so I want to download this embedded PDF/document in order to physically print it. The website allows me to view it as much as I want, but is asking me to fork over 25 + tax USD so i can download the document.
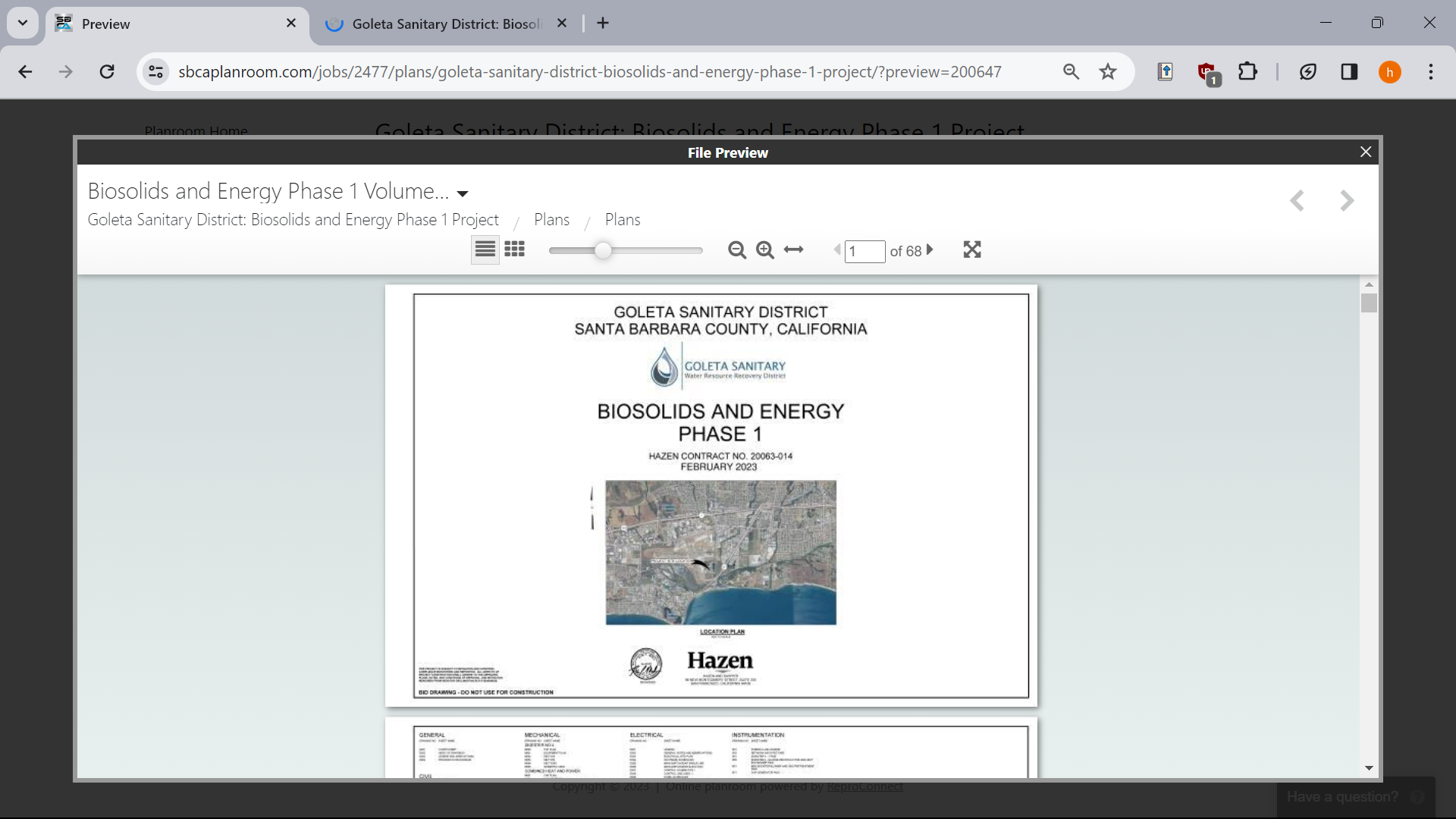
Obviously, i don’t want to do that, so I try to download the embedded document via inspect element. But, the weird thing is it not actually loading a pdf, but like really small pictures of each page:
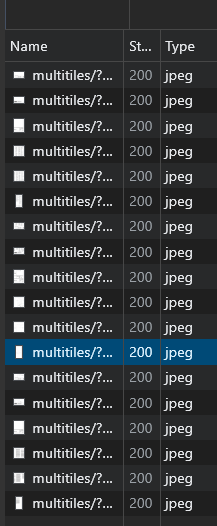
So, my question is basically how can I download this document in order to print it?
FOR LINUX, COMPLETE AND WORKING
- Install xdotool, AutoKey
- In Firefox get Save Screenshot: https://addons.mozilla.org/en-US/firefox/addon/savescreenshot/ Then, in Firefox Shortcuts add Ctrl+1 as a hotkey to capture visible page.
- Create a script for Autokey in Python, mine is:
import time import os import subprocess pages = dialog.input_dialog(title='', message='Number of pages:', default='5').data time.sleep(1) for k in range(1,int(pages)): subprocess.run(["xdotool", "key", "ctrl+1"]) # Plugin's hotkey time.sleep(2) subprocess.run(["xdotool", "click", "1"]) # Mouseclick time.sleep(2) subprocess.run(["xdotool", "key", "ctrl+1"]) # to screenshot the last one- In the bottom of a program, set a hotkey to launch it (I set it to Home).
- Open OP’s page and via Inspect Element find the link to embed. It’s https://www.sbcaplanroom.com/preview/2477/12610/200647
- Press F11, make the whole picture fit.
- Place mouse pointer over next page button, so it clicks each time.
- Lauch my Autokey script via Home button.
- Enter number of pages.
- See how it does it.
- Open screenshots directory in XnView, select them. Locate it’s BatchConvert tool, in Actions tab select a crop action and adjust it to pages’ margins. ACHTUNG The last one should be done differently, you can open it in XnV and crop this one alone.
- Use any tool to stitch them back together into a PDF. I’ve used PDF Arranger: https://github.com/pdfarranger/pdfarranger But some user down there said it crashed on 600-something pages document.
Compatible with any system? AFAIK autohotkey is windows-only
Damn, you are right.
I’ve found this Q-A thread about alternatives for Linux: https://unix.stackexchange.com/a/533392 I’d need to look into it.
Good god XnV and plugins aren’t.
Upd: AutoKey works. Scripts are on Python.
They say the op has magic powers!
Got any suggestions for image-to-pdf tools? The ones i’ve tried online all break after 300 pages or so
PDF Arranger: https://github.com/pdfarranger/pdfarranger
On the top there’s a button to import - Select images you want to add - Save as.
Turns out putting 602 jpeg files into any program is likely to make it freeze up.
In the end it made it?
I waited about 20 minutes and it eventually crashed. No luck.
Dammit. Are you on Windows? I can drop some pirated Acrobat for you to try.
600 seems like an overkill, maybe you can try to add a 100 at a time?
OP, I did it: https://files.catbox.moe/6eofj6.pdf
I will edit my reply with linux specifics.
My link was updated with a slightly better PDF. Comparison on max zoom: https://files.catbox.moe/5q3v4b.png A person with a 4k display could make better, but that’s what my screen is capable of.
Either way, it was a fun puzzle for my entry knowledge of linux\python\macroses and I feel I’ll use this method a couple of times myself. Hope someone would make use of it.
Holy shit dude you are awesome, thanks alot!
You are welcome 😉
👏 👏 👏
Fuck you and thank you, mr Spez ☺
Okay so, PDF documents are actually already “a collection of images” basically. This website is clearly trying to make it an extra step harder by loading the images individually as you browse the document. You could manually save/download all the images and use a tool to turn it back into a pdf. I haven’t heard of a tool that does this automatically, but it should be possible for a web scraper to make the GET requests sequentially then stitch the pdf back together.
I would go this route as well. As a developer this sounds easy enough. It you don’t get vertical sequences of images, but instead a grid of images, then I would apply traditional image stitching techniques. There are tons of libraries for that on github.
Just as a tiny nitpick: PDFs can be just a collection of images. If there’s text I would hope that they’re embedded as text or vectors, which is what would usually happen if you export a document from a program (that isn’t completely bs). So texts / vector graphics etc should not be images usually (unless you scan a document as a PDF - which I hate with a passion but can see that people prefer a single PDF over a collection of image files). Even then you could OCR the imges / PDF to make it searchable etc. Anyway in this case it seems to be a collection of images indeed __
Imagemagick can convert a series of images to single PDF: “convert page*.png mydoc.pdf”
I thought the
convertcommand didn’t do this, and that it was themagickone?
I’ve run into this before on archive.org, incredibly annoying.
I believe there are utilities that can capture and join together JPEGs into a PDF, but it seems they purposefully uploaded a very low res version to prevent that.
Hate to say, but I don’t see a way around it.
In this case the jpegs themselves change everytime you zoom in, so you zoom in a little it loads a new set of higher quality Jpegs.
Do you remember the tool you are talking about?
You could stitch together the pdfs with screen captures then, but that would be a royal pain in the ass.
ChromeCacheView is a step in the right direction, but nothing fully automatic. I’m also searching for a less manual solution.
You could write a script to scroll through the document at defined intervals, take screenshots, then have the script edit them together.
Of course by then, the time you’d have spent would be worth more than $25
Of course by then, the time you’d have spent would be worth more than $25
Yes, but you’d now have a script that can be used in the future as well. Automation is a magical thing, my friend.
To semi automate downloading all the pages, try jdownloader 2. You probably need to paste the url into jdownloader manually for jdownloader to load all the downloadable bits it finds on the page.
Think you’ll have to take screen shots. That’s a pretty good way of stopping you downloading it.
Or just email and ask them for a copy. It’s not Harry Potter or anything, there’s no reason it shouldn’t be free if you ask the right person.









{kind=link}
{kind=link}